魔改 babel-parser 实现自定义 JS 语法
上篇文章 《自己动手撸一个 Babel 插件》 讲述了如何构造 Babel 插件修改 JS 语法树,这篇文章将通过调试并魔改 babel-parser 源码来实现任何自定义的 JS 语法。
准备工作
如果对 Babel 项目不太熟悉的同学可以先阅读下面两篇文章,下面这篇是上面的译文 + 学习笔记。这两篇文章给了我很大启发,后面我也将从自己亲身实践的一个案例入手,不断深入 Babel 的魔法世界。
如果对 AST 节点定义不了解的,可以参考我之前的文章 JS 语法树学习(全)
一个想法
一直觉得 Python 的 list 语法设计的是真的好用,和 JS 的 Array 对比一下:
// python
a = [x for x in range(10)]
// javascript
const a = Array(10).fill(0).map((item, index) => index)
// python
[1,2,3,4,5][1:3]
// javascript
[1,2,3,4,5].slice(1,3)
有没有觉得 Python 写起来更简洁一些,但是像 Python 这样的切片表达式不符合 Javascript AST 规范,你可以在 Babel AST Explorer 查看结果。

我们看到 babel-parser 无法解析这样的数组切片语法,因此我们无法通过 Babel 插件实现从 a[1:3] 到 a.slice(1,3) 的转化。
从 Babel 源码入手
首先 fork Babel 源码,并 Clone 到本地,执行 make bootstrap && make build。如果对 Babel 源码结构不了解的童鞋可以看上面提到的两篇文章。然后在项目路径新建 packages/babel-parser/test.js
const { parse } = require("./lib");
parse(`a[1:3]`, { sourceType: "module" });
执行 node test.js,发现报错与刚才网页上的一致:
SyntaxError: Unexpected token, expected "]" (1:3)
at Parser._raise (/Users/Vincent/Playground/babel/packages/babel-parser/lib/index.js:747:17)
at Parser.raiseWithData (/Users/Vincent/Playground/babel/packages/babel-parser/lib/index.js:740:17)
at Parser.raise (/Users/Vincent/Playground/babel/packages/babel-parser/lib/index.js:734:17)
at Parser.unexpected (/Users/Vincent/Playground/babel/packages/babel-parser/lib/index.js:8812:16)
at Parser.expect (/Users/Vincent/Playground/babel/packages/babel-parser/lib/index.js:8798:28)
at Parser.parseSubscript (/Users/Vincent/Playground/babel/packages/babel-parser/lib/index.js:9743:14)
at Parser.parseSubscripts (/Users/Vincent/Playground/babel/packages/babel-parser/lib/index.js:9696:19)
at Parser.parseExprSubscripts (/Users/Vincent/Playground/babel/packages/babel-parser/lib/index.js:9679:17)
at Parser.parseMaybeUnary (/Users/Vincent/Playground/babel/packages/babel-parser/lib/index.js:9653:21)
at Parser.parseExprOps (/Users/Vincent/Playground/babel/packages/babel-parser/lib/index.js:9523:23) {
loc: Position { line: 1, column: 3 },
pos: 3
}
VSCode 配置
安装插件:
- vscode-flow-ide
- ESLint
新建 .vscode/settings.json,开启 flow 需要关闭 js 报错,启用 eslint
{
"javascript.validate.enable": false,
"eslint.format.enable": true,
"editor.codeActionsOnSave": {
"source.fixAll.eslint": true
},
"[javascript]": {
"editor.defaultFormatter": "dbaeumer.vscode-eslint"
}
}
新建 .vscode/launch.json,添加调试入口文件。
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "Launch Program",
"program": "${workspaceFolder}/packages/babel-parser/test.js"
}
]
}
断点调试
在 packages/babel-parser/lib/index.js 入口函数 parse 添加断点。
function parse(input, options) {
...
-> return getParser(options, input).parse();
}
这个入口函数会设置默认的 options 配置,最终调用 getParser().parse() 来解析
function getParser(options, input) {
let cls = Parser;
...
-> return new cls(options, input);
}
进入 Parser 类,我们发现 Parser::parse 函数创建了 AST 的根节点 Program 和更上层的 File 节点,然后通过父类 StatementParser 的 parseTopLevel 函数开始解析最外层的语句到 File 节点。
class Parser extends StatementParser {
...
parse() {
...
const file = this.startNode();
const program = this.startNode();
this.nextToken();
file.errors = null;
-> this.parseTopLevel(file, program);
file.errors = this.state.errors;
return file;
}
}
我梳理了一下 Parser 类的继承关系:
Parser <: StatementParser <: ExpressionParser <: LValParser
<: NodeUtils <: UtilParser <: Tokenizer <: ParserError
<: CommentsParser <: BaseParser
进入 StatementParser::parseTopLevel,这个函数调用 parseBlockBody,遇到 types.eof 停止,然后封装 Program、File 节点。
parseTopLevel(file, program) {
program.sourceType = this.options.sourceType;
program.interpreter = this.parseInterpreterDirective();
-> this.parseBlockBody(program, true, true, types.eof);
...
file.program = this.finishNode(program, "Program");
file.comments = this.state.comments;
if (this.options.tokens) file.tokens = this.tokens;
return this.finishNode(file, "File");
}
进入 StatementParser::parseBlockBody
parseBlockBody(node, allowDirectives, topLevel, end, afterBlockParse) {
const body = node.body = [];
const directives = node.directives = [];
-> this.parseBlockOrModuleBlockBody(body, allowDirectives ? directives : undefined, topLevel, end, afterBlockParse);
}
进入 StatementParser::parseBlockOrModuleBlockBody,省略了部分代码,主逻辑还是很清晰的,就是逐语句解析并推入 AST 到 Program.body
parseBlockOrModuleBlockBody(body, directives, topLevel, end, afterBlockParse) {
...
while (!this.match(end)) {
-> const stmt = this.parseStatement(null, topLevel);
...
body.push(stmt);
}
...
this.next();
}
进入 StatementParser::parseStatement,这里先判断了 Type[“@”] 解析装饰器语法,然后解析语句内容。
parseStatement(context, topLevel) {
if (this.match(types.at)) {
this.parseDecorators(true);
}
-> return this.parseStatementContent(context, topLevel);
}
进入 StatementParser::parseStatementContent,这是解析语句节点的关键函数,从这个大大的 switch 语句就能看出,如果对某些 AST 节点定义不了解可以参考我之前的文章 《JS 语法树学习(全)》
parseStatementContent(context, topLevel) {
...
switch (starttype) {
case types._break:
case types._continue:
return this.parseBreakContinueStatement(node, starttype.keyword);
case types._debugger:
return this.parseDebuggerStatement(node);
case types._do:
return this.parseDoStatement(node);
case types._for:
return this.parseForStatement(node);
case types._function:
...
return this.parseFunctionStatement(node, false, !context);
case types._class:
...
return this.parseClass(node, true);
case types._if:
return this.parseIfStatement(node);
case types._return:
return this.parseReturnStatement(node);
case types._switch:
return this.parseSwitchStatement(node);
case types._throw:
return this.parseThrowStatement(node);
case types._try:
return this.parseTryStatement(node);
case types._const:
case types._var:
...
return this.parseVarStatement(node, kind);
case types._while:
return this.parseWhileStatement(node);
case types._with:
return this.parseWithStatement(node);
case types.braceL:
return this.parseBlock();
case types.semi:
return this.parseEmptyStatement(node);
case types._export:
case types._import:
...
default:
if (this.isAsyncFunction()) {
...
return this.parseFunctionStatement(node, true, !context);
}
}
const maybeName = this.state.value;
-> const expr = this.parseExpression();
if (starttype === types.name && expr.type === "Identifier" && this.eat(types.colon)) {
return this.parseLabeledStatement(node, maybeName, expr, context);
} else {
return this.parseExpressionStatement(node, expr);
}
}
如果没有被解析语句的 case 囊括并 return 跳出,就会流转到下面的表达式解析 parseExpression 并包装成 ExpressionStatement 或者 LabeledStatement 语句节点。
我们测试的代码是 a[1:3],应该会进入 ExpressionParser::parseExpression 并抛出异常:
parseExpression(noIn, refExpressionErrors) {
const startPos = this.state.start;
const startLoc = this.state.startLoc;
const expr = this.parseMaybeAssign(noIn, refExpressionErrors);
if (this.match(types.comma)) {
const node = this.startNodeAt(startPos, startLoc);
node.expressions = [expr];
while (this.eat(types.comma)) {
node.expressions.push(this.parseMaybeAssign(noIn, refExpressionErrors));
}
this.toReferencedList(node.expressions);
return this.finishNode(node, "SequenceExpression");
}
return expr;
}
这里我们可以看出除了像 1, a>b, !c 这样的 SequenceExpression (可以理解为多个表达式用逗号相连组成的一个大的表达式),其他都会被 ExpressionParser::parseMaybeAssign 解析,到了这里,我们的解决方案就有了。
创建 JS 的切片语法
我们可以在 https://python-ast-explorer.com/ 查看 Python 的语法树结构
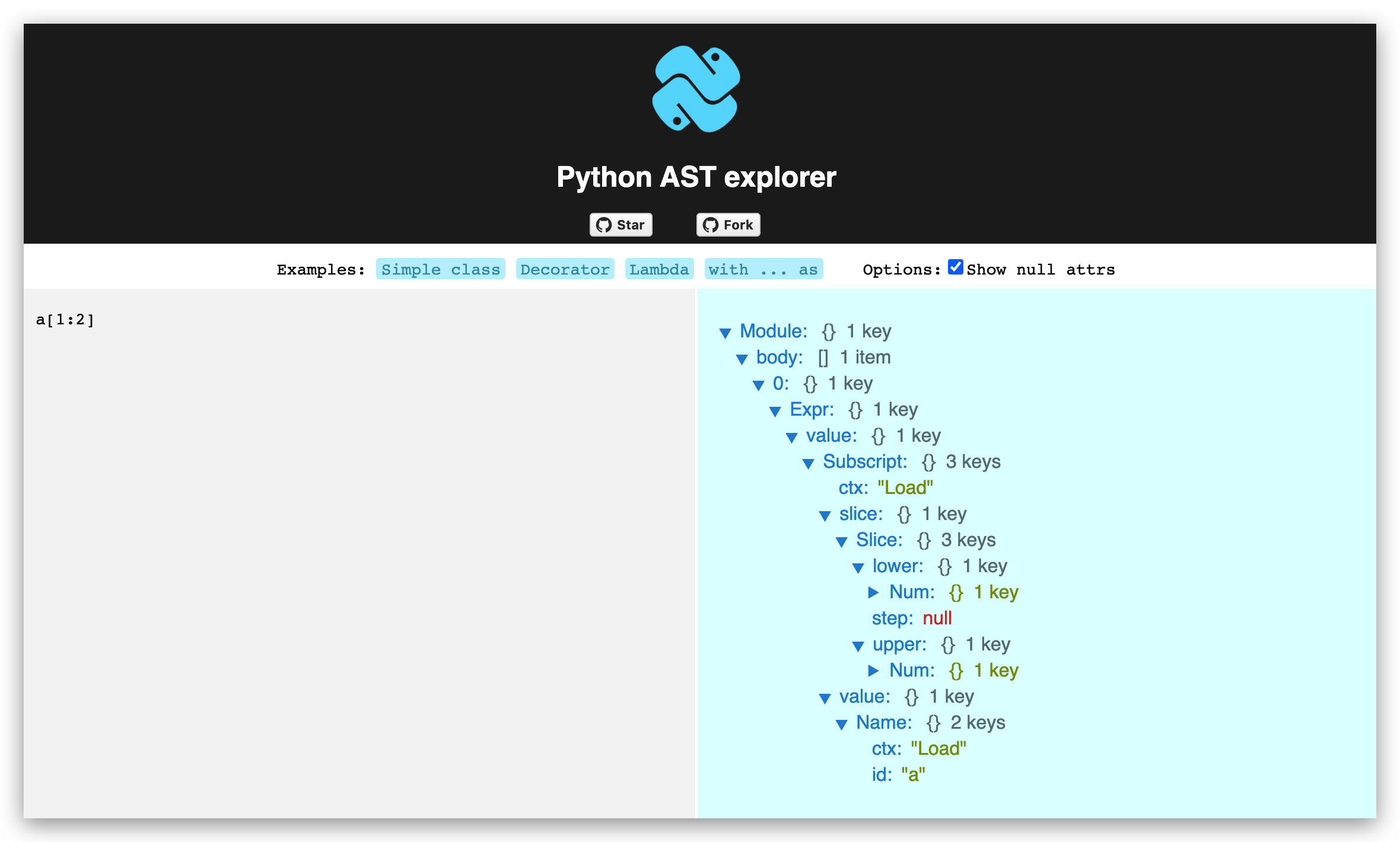
依葫芦画瓢,修改 ExpressionParser::parseExpression:
parseExpression(noIn, refExpressionErrors) {
const startPos = this.state.start;
const startLoc = this.state.startLoc;
const expr = this.parseMaybeAssign(noIn, refExpressionErrors);
if (this.match(types.comma)) {
const node = this.startNodeAt(startPos, startLoc);
node.expressions = [expr];
while (this.eat(types.comma)) {
node.expressions.push(this.parseMaybeAssign(noIn, refExpressionErrors));
}
this.toReferencedList(node.expressions);
return this.finishNode(node, "SequenceExpression");
}
// 判断冒号
if (this.match(types.colon)) {
// 新建空节点
const node = this.startNodeAt(startPos, startLoc);
// 上面解析的冒号左边的表达式
node.lower = expr;
// 吃掉冒号
this.eat(types.colon);
// 解析冒号右边的表达式
node.upper = this.parseMaybeAssign(noIn, refExpressionErrors);
// 完成节点,封装 Type 为 SliceExpression
return this.finishNode(node, "SliceExpression");
}
return expr;
}
现在我们的 babel-parser 就有了解析我们 “自定义切片语法” 的能力,打印一下 AST:
File {
program: Program {
body: [
ExpressionStatement {
expression: MemberExpression {
object: Identifier { name: 'a' },
property: Node {
type: 'SliceExpression',
lower: NumericLiteral { value: 1 },
upper: NumericLiteral { value: 3 },
}
}
}
]
}
}
创建 Transform 插件
目前我们通过魔改 babel-parser 能够顺利的生成语法树,但是我们最终的目的是将 a[1:3] 解析成 a.slice(1,3),如果对编写 Babel 插件不熟悉的童鞋可以参考我之前的文章 《自己动手撸一个 Babel 插件》
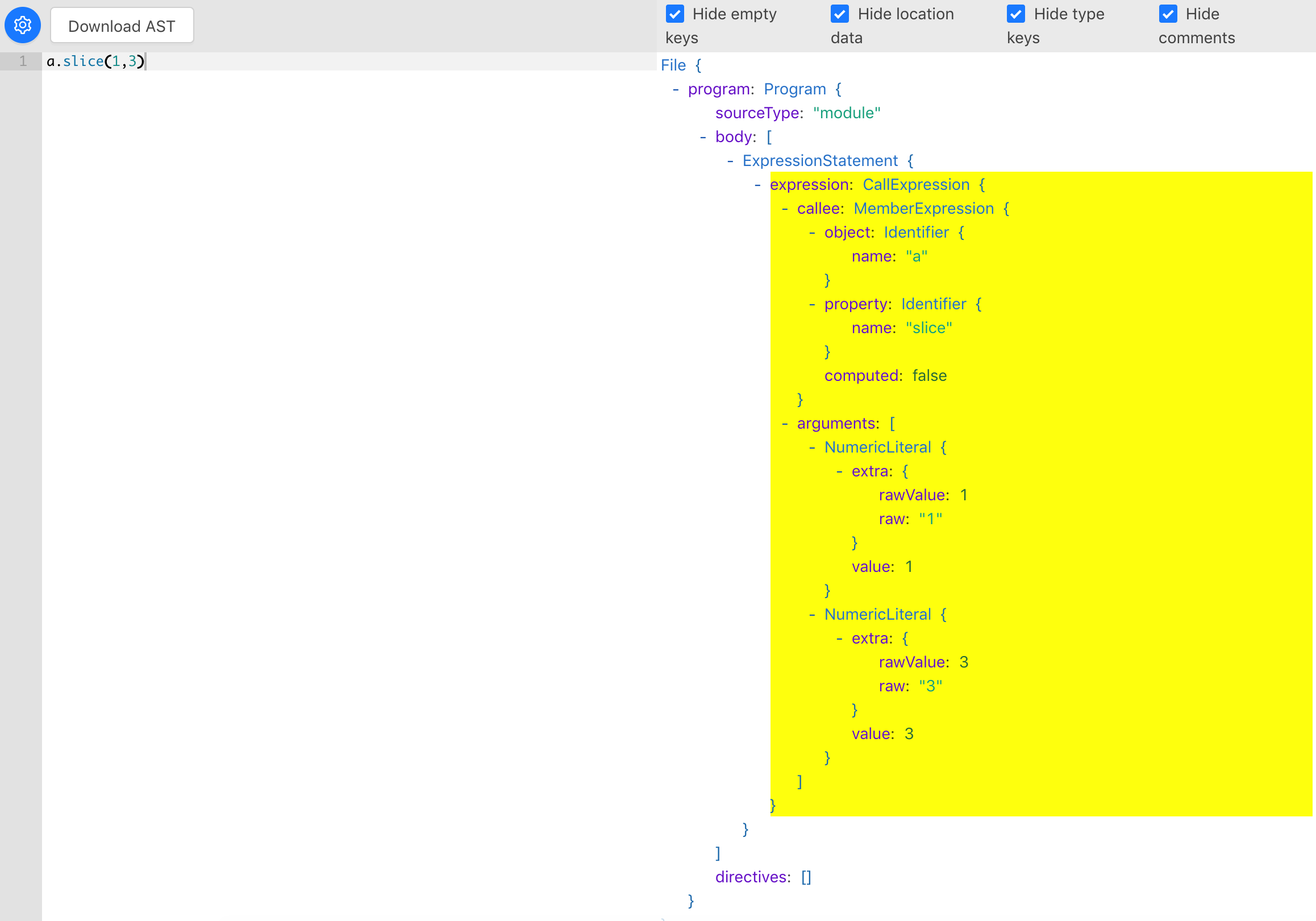
我们查看一下 a.slice(1,3) 的 AST,只要做一些小小的调整就成了:
const types = require('@babel/types');
const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const generator = require('@babel/generator').default;
const transformSliceExpressionPlugin = {
visitor: {
ExpressionStatement(path) {
if (path.node.expression.type === 'MemberExpression' && path.node.expression.property.type === 'SliceExpression') {
const { object, property } = path.node.expression;
const { lower, upper } = property;
const memberExpression = types.memberExpression(object, types.identifier('slice'))
const callExpression = types.callExpression(memberExpression, [lower, upper]);
const expressionStatement = types.expressionStatement(callExpression);
path.replaceWith(expressionStatement)
}
}
}
}
// test
const code = 'a[1:3]';
const ast = parser.parse(code);
traverse(ast, transformSliceExpressionPlugin.visitor);
const result = generator(ast);
console.log(result.code);
看到打印结果 a.slice(1, 3)